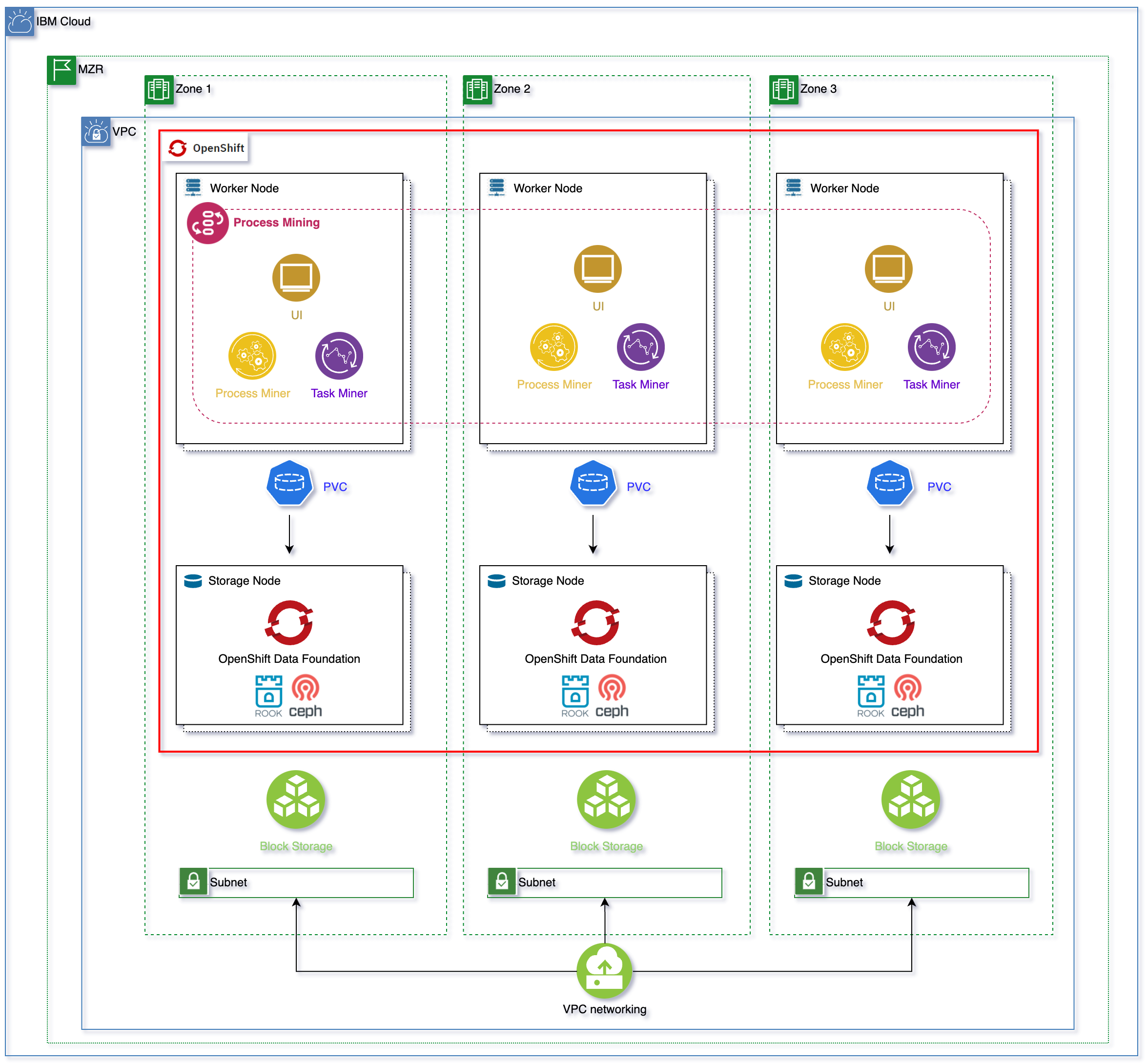
Machine learning has become an integral part of countless industries, revolutionizing the way we process, analyze, and interpret data. One crucial aspect of implementing machine learning models is understanding the architecture diagram. In this blog article, we will delve deep into the intricacies of machine learning architecture diagrams, providing you with a comprehensive understanding of this essential concept.
The Basics of Machine Learning Architecture
In this section, we will explore the fundamental concepts of machine learning architecture, including its components and their roles. From the input layer to the output layer, we will break down the key elements that make up a machine learning architecture diagram.





The Input Layer: Receiving and Preparing Data
The input layer is the first layer in a machine learning architecture diagram, responsible for receiving and preparing data for further processing. This layer takes in raw data, which may come in various formats such as images, text, or numerical values. It performs initial preprocessing steps such as data cleaning, normalization, and feature extraction to ensure the data is in a suitable format for the subsequent layers.
Hidden Layers: Extracting and Transforming Information
The hidden layers in a machine learning architecture diagram are the intermediate layers between the input and output layers. These layers are responsible for extracting and transforming information from the input data, enabling the model to learn patterns, relationships, and representations. Each hidden layer consists of a set of neurons, which perform computations using weights and activation functions to produce output values.
The Output Layer: Making Predictions or Decisions
The output layer is the final layer in a machine learning architecture diagram, responsible for making predictions or decisions based on the processed input data. The number of neurons in the output layer depends on the nature of the problem being solved. For example, in a binary classification problem, there would be one neuron in the output layer representing the probability of belonging to one class, while in a multi-class classification problem, there would be multiple neurons representing the probabilities of each class.
Data Preprocessing and Feature Engineering
Data preprocessing and feature engineering play a vital role in optimizing machine learning models. This section will discuss various techniques used to preprocess data and engineer relevant features, ensuring that your machine learning architecture is robust and efficient.
Data Cleaning: Handling Missing Values and Outliers
Data cleaning is an essential step in data preprocessing, where missing values and outliers are handled. Missing values can be imputed using techniques such as mean imputation, median imputation, or using advanced imputation algorithms. Outliers, which are extreme values that deviate significantly from the rest of the data, can be detected and treated by methods like z-score, interquartile range, or clustering-based approaches.
Data Normalization: Scaling Features
Data normalization is the process of scaling features to a consistent range, preventing certain features from dominating the model’s learning process due to their larger magnitudes. Common normalization techniques include min-max scaling, z-score normalization, and robust scaling. These techniques ensure that all features contribute equally to the model’s decision-making process.
Feature Extraction: Transforming Data Into Meaningful Representations
Feature extraction involves transforming the raw input data into a set of meaningful representations that capture the underlying patterns and relationships. Techniques such as principal component analysis (PCA), linear discriminant analysis (LDA), and autoencoders can be used to extract relevant features that contribute most to the model’s performance. This process reduces the dimensionality of the data and focuses on the most informative aspects.
Feature Selection: Choosing the Most Relevant Features
Feature selection aims to identify and select the most relevant features from a larger set of available features. This process helps reduce the complexity and computational requirements of the model while improving its generalization capabilities. Techniques such as filter methods, wrapper methods, and embedded methods can be employed to evaluate the importance of each feature and select the subset that contributes most to the model’s predictive power.
Model Selection and Evaluation
Choosing the right machine learning model for your specific problem is crucial for achieving accurate results. In this section, we will explore various popular machine learning algorithms and evaluate their performance metrics, helping you make informed decisions when selecting the most suitable model for your architecture diagram.
Supervised Learning Algorithms: Regression and Classification
Supervised learning algorithms are used for problems where the target variable is known, and the model learns to map input features to the corresponding output. Regression algorithms, such as linear regression, decision trees, and support vector regression, are used for continuous target variables. Classification algorithms, such as logistic regression, random forests, and neural networks, are used for categorical or binary target variables. We will discuss the strengths, weaknesses, and considerations for each algorithm, allowing you to choose the best fit for your problem.
Unsupervised Learning Algorithms: Clustering and Dimensionality Reduction
Unsupervised learning algorithms are used for problems where the target variable is unknown and the model learns to discover hidden patterns or structures in the data. Clustering algorithms, such as K-means, hierarchical clustering, and DBSCAN, group similar instances together based on their features. Dimensionality reduction algorithms, such as principal component analysis (PCA), t-SNE, and autoencoders, reduce the dimensionality of the data while preserving its important characteristics. We will explore the applications and considerations for each algorithm in unsupervised learning scenarios.
Evaluation Metrics: Assessing Model Performance
Evaluating the performance of machine learning models is crucial to understand how well they generalize to unseen data. Common evaluation metrics for regression problems include mean squared error (MSE), root mean squared error (RMSE), and R-squared. For classification problems, metrics such as accuracy, precision, recall, and F1 score are used. We will discuss the interpretation and significance of these metrics and guide you in selecting the appropriate evaluation method for your specific problem.
Overfitting and Underfitting: Balancing Model Complexity
Overfitting and underfitting are common challenges in machine learning, where the model either learns too much from the training data, leading to poor generalization, or fails to capture the underlying patterns, resulting in high bias. Techniques such as regularization, cross-validation, and early stopping can be employed to mitigate these issues and strike a balance between model complexity and performance. We will explore these techniques and provide insights into identifying and addressing overfitting and underfitting problems.
Training and Testing the Model
Training and testing your machine learning model are essential steps in the architecture diagram. We will guide you through the process of splitting your data, training your model, and evaluating its performance. Understand the critical aspects of model training to achieve optimal results.
Data Splitting: Training, Validation, and Testing Sets
Before training a machine learning model, it is crucial to split the available data into training, validation, and testing sets. The training set is used to train the model, the validation set is used to fine-tune hyperparameters and make decisions on model selection, and the testing set is used to evaluate the final performance of the model. We will discuss techniques such as random splitting, stratified splitting, and cross-validation for splitting the data effectively.
Model Training: Optimization and Learning
Model training involves optimizing the model’s parameters to minimize the chosen loss or error function. This process is typically achieved through iterative optimization algorithms such as gradient descent, stochastic gradient descent, or adaptive algorithms like Adam. We will explain the inner workings of these optimization algorithms and discuss techniques for preventing issues such as vanishing gradients or exploding gradients during training.
Model Evaluation: Assessing Performance on Unseen Data
After training the model, it is essential to evaluate its performance on unseen data to assess its generalization capabilities. This is done using the testing set, which was previously set aside. By analyzing metrics such as accuracy, precision, recall, or mean squared error, you can determine how well the model performs on data it has never encountered before. We will guide you on interpreting these metrics and provide insights into improving model performance based on the evaluation results.
Hyperparameter Tuning
Hyperparameters significantly impact the performance of your machine learning model. In this section, we will discuss the importance of hyperparameter tuning and provide you with effective techniques to fine-tune your model, maximizing its accuracy and efficiency.
Understanding Hyperparameters: Impact on Model Behavior
Hyperparameters are parameters that are not learned from the data but are set manually before training the model. These parameters control aspects such as learning rate, regularization strength, batch size, and network architecture. Understanding the impact of hyperparameters on the model’s behavior is crucial for achieving optimal performance. We will explain the role and significance of various hyperparameters in different machine learning algorithms.
Grid Search: Systematic Hyperparameter Exploration
Grid search is a systematic approach to hyperparameter tuning, where different combinations of hyperparameters are evaluated on a validation set. This technique exhaustively searches through a predefined grid of hyperparameter values to find the optimal combination that maximizes the model’s performance. We will guide you through the process of setting up a grid search and interpreting the results to select the best hyperparameter values for your model.
Random Search: Efficient Hyperparameter Exploration
Random search is
Random Search: Efficient Hyperparameter Exploration
Random search is an alternative approach to hyperparameter tuning that randomly samples from a predefined range of hyperparameter values. Compared to grid search, random search is more efficient when the hyperparameter space is large, as it explores different combinations in a more stochastic manner. We will discuss the benefits and considerations of using random search and provide guidance on implementing it effectively.
Bayesian Optimization: Intelligent Hyperparameter Search
Bayesian optimization is a more advanced technique for hyperparameter tuning that utilizes probabilistic models to intelligently search the hyperparameter space. It uses previous observations of hyperparameter-performance pairs to model the underlying function and suggest promising regions to explore. Bayesian optimization is particularly useful when the evaluation of each hyperparameter configuration is computationally expensive. We will explore the principles behind Bayesian optimization and discuss how to implement it for efficient hyperparameter tuning.
Automated Hyperparameter Tuning: Using Libraries and Tools
Automated hyperparameter tuning libraries and tools provide convenient ways to explore and optimize hyperparameters without manually implementing the tuning process. Libraries like scikit-learn’s GridSearchCV and RandomizedSearchCV, as well as tools like Optuna and Hyperopt, offer efficient and user-friendly interfaces for hyperparameter tuning. We will introduce some popular libraries and tools and guide you on how to leverage them for effective hyperparameter optimization.
Optimization Techniques
Optimization techniques play a vital role in enhancing the performance of your machine learning architecture. This section will cover various optimization algorithms and strategies that can be employed to improve your model’s speed, precision, and generalization capabilities.
Gradient Descent: Optimizing Model Parameters
Gradient descent is a widely used optimization algorithm that aims to find the optimal set of model parameters by iteratively adjusting them in the direction of steepest descent of the loss function. We will explain the intuition behind gradient descent, discuss different variants such as batch gradient descent, stochastic gradient descent, and mini-batch gradient descent, and provide insights into strategies for setting the learning rate and dealing with convergence issues.
Regularization: Controlling Model Complexity
Regularization techniques are employed to prevent overfitting and improve the generalization capabilities of machine learning models. L1 regularization (Lasso), L2 regularization (Ridge), and elastic net regularization are commonly used regularization techniques. We will discuss the principles behind regularization, explain how it works to control model complexity, and guide you on selecting the appropriate regularization technique for your specific problem.
Dropout: Reducing Overfitting in Neural Networks
Dropout is a regularization technique specifically designed for neural networks. It randomly drops out a fraction of the neurons during training, forcing the network to learn redundant representations and preventing overfitting. We will explore the concept of dropout, explain its benefits in reducing overfitting, and provide insights into setting the dropout rate and effectively implementing dropout in neural network architectures.
Batch Normalization: Accelerating Training and Improving Generalization
Batch normalization is a technique used to accelerate the training process and improve the generalization capabilities of neural networks. It normalizes the activations of each layer by subtracting the batch mean and dividing by the batch standard deviation. This ensures that the inputs to subsequent layers are within a suitable range, helping the network learn more effectively. We will discuss the intuition behind batch normalization, explain its advantages, and guide you on implementing batch normalization in your neural network architectures.
Early Stopping: Preventing Overfitting by Monitoring Validation Loss
Early stopping is a technique used to prevent overfitting by monitoring the validation loss during training. It involves stopping the training process once the validation loss starts to increase, indicating that the model’s performance on unseen data is deteriorating. We will explain how to implement early stopping effectively, discuss considerations for determining the optimal stopping point, and provide insights into using patience and learning rate scheduling to improve early stopping performance.
Deployment and Scalability
Deploying your machine learning model is the final step in the architecture diagram. We will explore different deployment options and discuss scalability challenges that may arise while implementing machine learning models in real-world scenarios.
Model Deployment: Integration into Production Systems
Model deployment involves integrating the trained machine learning model into production systems, allowing it to make predictions or decisions in real-time. We will discuss different deployment options such as deploying as a web service, embedding the model into mobile applications, or running it on edge devices. Considerations such as model serialization, API design, and security will be addressed to ensure a seamless and efficient deployment process.
Scalability: Handling Large Datasets and High Traffic
Scalability is a critical aspect of deploying machine learning models, especially when dealing with large datasets or high traffic scenarios. We will explore techniques for handling large datasets, such as distributed computing frameworks like Apache Spark, data streaming platforms like Apache Kafka, and cloud-based solutions like AWS S3 and Google Cloud Storage. Additionally, strategies for handling high traffic and ensuring model performance and availability, such as load balancing and containerization, will be discussed.
Monitoring and Maintenance: Ensuring Model Performance
Once a machine learning model is deployed, it is essential to monitor its performance and maintain its accuracy over time. We will explore techniques for monitoring model performance, such as tracking metrics, logging predictions, and setting up alerts for anomalies. Additionally, strategies for model retraining, updating, and versioning will be discussed to ensure that the deployed model remains up-to-date and continues to provide accurate predictions.
Ethical Considerations in Machine Learning
As machine learning continues to advance, ethical considerations become increasingly important. In this section, we will address the ethical implications of machine learning architecture, including bias, privacy concerns, and fair decision-making processes.
Bias in Machine Learning: Addressing Discrimination and Fairness
Machine learning models can inadvertently inherit biases from the data they are trained on, leading to discriminatory outcomes. We will discuss techniques for identifying and mitigating bias in machine learning, such as dataset preprocessing, algorithmic fairness measures, and explainable AI. Ensuring fairness and avoiding discrimination are crucial aspects of responsible machine learning implementation.
Privacy and Data Protection: Safeguarding Sensitive Information
Machine learning models often rely on large amounts of data, raising concerns about privacy and data protection. We will explore techniques for privacy-preserving machine learning, such as differential privacy, federated learning, and secure multi-party computation. Additionally, we will discuss considerations for data anonymization, consent, and compliance with regulations like GDPR to ensure the responsible handling of sensitive information.
Transparency and Explainability: Interpreting Model Decisions
Transparency and explainability are crucial for building trust and accountability in machine learning models. We will discuss techniques for interpreting model decisions, such as feature importance analysis, model-agnostic interpretability methods, and rule extraction. By providing explanations for model predictions and decisions, we can ensure transparency and enable users to understand and challenge the outcomes.
Case Studies of Successful Machine Learning Architectures
Examining real-world examples is an excellent way to gain practical insights into machine learning architecture diagrams. This section will showcase various case studies that highlight successful machine learning architectures across different industries, providing you with inspiration and valuable lessons.
Healthcare: Predictive Analytics for Disease Diagnosis
In the healthcare industry, machine learning architectures have been successfully applied to predict diseases, such as cancer, diabetes, and cardiovascular conditions. We will explore case studies where machine learning models have demonstrated high accuracy in diagnosing diseases based on medical imaging, patient records, and genetic data. These examples will showcase the potential of machine learning in improving healthcare outcomes.
E-commerce: Recommender Systems for Personalized Shopping
E-commerce platforms rely on machine learning architectures to provide personalized recommendations to their customers. We will delve into case studies where machine learning models have been used to analyze user preferences, browsing history, and purchase behavior to generate accurate and relevant product recommendations. These examples will demonstrate the impact of machine learning in enhancing the user experience and driving sales in the e-commerce industry.
Finance: Fraud Detection and Risk Assessment
Machine learning architectures have proven to be effective in detecting fraudulent transactions and assessing financial risks. We will examine case studies where machine learning models have been used to analyze patterns, anomalies, and historical data to identify fraudulent activities and evaluate creditworthiness. These examples will highlight the importance of machine learning in safeguarding financial systems and protecting against fraudulent behavior.
Transportation: Traffic Prediction and Route Optimization
Machine learning architectures can significantly improve transportation systems by providing accurate traffic predictions and optimizing route planning. We will explore case studies where machine learning models have been employed to analyze historical traffic data, weather conditions, and real-time information to predict traffic congestion and suggest optimal routes. These examples will showcase the potential of machine learning in improving transportation efficiency and reducing travel time.
Future Trends and Innovations
Machine learning is an ever-evolving field, constantly introducing new trends and innovations. In this final section, we will explore the future of machine learning architecture, discussing emerging technologies and potential advancements that will shape the landscape of this fascinating field.
Deep Learning: Advancements in Neural Network Architectures
Deep learning, a subset
Deep Learning: Advancements in Neural Network Architectures
Deep learning, a subset of machine learning, has gained significant attention in recent years due to its ability to learn complex patterns and representations. We will explore emerging trends and innovations in deep learning, such as convolutional neural networks (CNNs) for computer vision tasks, recurrent neural networks (RNNs) for sequential data analysis, and transformer models for natural language processing. These advancements in neural network architectures are driving breakthroughs in various domains and opening up new possibilities for machine learning applications.
Explainable AI: Interpretable and Transparent Models
Explainable AI is an area of research focused on developing machine learning models that provide human-understandable explanations for their predictions and decisions. We will discuss emerging techniques and methods for building explainable models, such as rule-based models, attention mechanisms, and model-agnostic interpretability. Explainable AI is essential for building trust, ensuring fairness, and meeting regulatory requirements in domains where interpretability is crucial.
AutoML: Automated Machine Learning
AutoML, or automated machine learning, is an emerging field that aims to automate the process of building machine learning models. We will explore the advancements in AutoML techniques, such as neural architecture search (NAS), hyperparameter optimization, and automated feature engineering. AutoML tools and platforms are making machine learning more accessible to non-experts and accelerating the development of effective machine learning architectures.
Federated Learning: Collaborative and Privacy-Preserving Models
Federated learning is a distributed learning approach that allows multiple parties to collaboratively train a machine learning model without sharing their raw data. We will discuss the potential of federated learning for privacy-preserving machine learning, exploring its applications in domains where data privacy is a significant concern, such as healthcare, finance, and IoT. Federated learning enables the development of models with improved performance while maintaining data privacy and security.
Edge Computing: Machine Learning at the Edge
Edge computing involves performing computations and running machine learning models on devices at the edge of the network, such as smartphones, IoT devices, and edge servers. We will explore the advancements in edge computing and its implications for machine learning architectures. Running models at the edge reduces latency, saves bandwidth, and enables real-time decision-making in applications where immediate responses are critical, such as autonomous vehicles and smart homes.
Interdisciplinary Collaborations: Fusion of Machine Learning and Other Fields
Machine learning is increasingly collaborating with other fields, such as robotics, biology, and social sciences, to tackle complex problems and drive innovation. We will discuss emerging interdisciplinary collaborations and their impact on machine learning architecture. For example, the fusion of machine learning and robotics is enabling the development of intelligent robots, while the integration of machine learning and biology is advancing the understanding of disease mechanisms and drug discovery.
In conclusion, understanding the machine learning architecture diagram is crucial for successfully implementing machine learning models. With a firm grasp of the fundamental concepts, data preprocessing techniques, model selection, optimization strategies, and ethical considerations, you will be well-equipped to design robust and efficient architectures that drive meaningful insights from your data. Stay ahead of the curve in this rapidly evolving field and unlock the true potential of machine learning.